7 Institute development
Rachael Samberg and Timothy Vollmer
This chapter explores how we developed the Institute. First, we explain our overall design thinking approach to the Institute instruction. Second, we discuss our process for recruiting faculty and soliciting applicants. Third, we detail how we selected participants. Fourth, we explain how we financially supported both participants and instructors for taking part in the weeklong Institute. Fifth, we outlined our approach to internal and public communications. Finally, we talk about the pre-Institute tasks required of the participants.
Design thinking approach
To help TDM scholars and digital humanities (DH) professionals build skills tailored for their own DH research agendas, the Institute incorporated a “design thinking” structure reliant upon experiential methodologies. Building LLTDM modeled five stages in design thinking: empathize, define, ideate, prototype, and test.
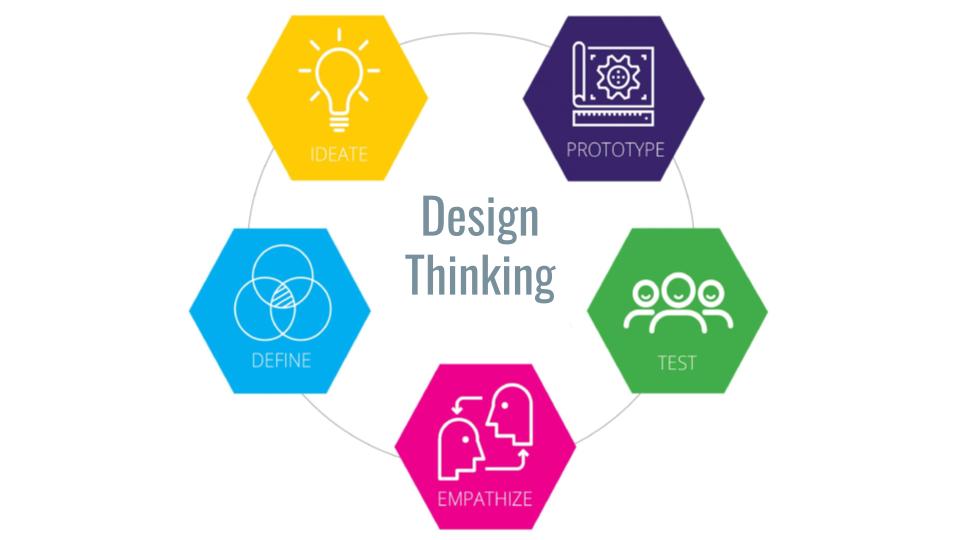
While we will discuss in detail the day-to-day activities in the next chapter, from a high level we started the first day of the Institute by building out our understanding of participants’ experiences with TDM. This helped expand upon what the project team learned from applicants through their applications and questionnaire responses. Day one’s “empathize” activities served as an opportunity for participants to get to know each other and to start learning from each other early in our time together. We believed that building trust and common understanding across the cohort led to more robust discussion sessions and collaborative inquiry throughout the Institute.
For days two and three, we cycled iteratively through the “define” and “ideate” phases of the design thinking rubric. The instructors framed and defined a range of different topical TDM issues and literacies through asynchronous videos, and then we used our synchronous time to work through case studies and “putting it together” exercises. This was intended to help strategize how participants could apply their learning to real-word challenges they faced in conducting or supporting TDM research within their home institutions.
On the final day of the Institute, we spent time together prototyping the implementation plans. This was the hands-on time to apply the week’s sessions to the participants own work and situated local contexts. We’ll be staying connected post-Institute to learn from each other’s outcomes as implementation plans evolve.
Recruiting faculty and participants
Faculty
Our Institute project team were composed of legal experts, librarians, faculty, and scholars immersed in digital humanities and research literacies. They were recruited through professional connections and networks. This set of 15 faculty hailed from more than a dozen North American universities and institutions. Faculty contributed to Institute administration and curricular design, and served as instructors during the Institute. Faculty were designated as: humanities researchers (“HR”), librarians (“L”), or legal experts (“LE”). Their real-world roles straddled these boundaries (e.g. some legal experts are also librarians); yet, the divisions ensured that Institute sessions are led by a set of experts who collectively offer a full range of relevant DH expertise.
The project team was led by a Project Director who oversaw curricular design and execution, administrative and operational aspects of Building LLTDM, and also served as one of the instructors during the Institute. The project team was supported by a Project Manager who coordinated design and execution of the Institute, streamlined administrative and operational aspects, and also served as an Institute instructor.
We had a legal expert on call via e-mail during the Institute to field any questions that instructors were unable to answer in real time.
Participants
We developed a project website to host information about the Institute application process, timeline, and criteria. We advertised the Institute opportunity on the Building LLTDM blog, via digital humanities and library-related email lists, and via social media.
The Institute supported 32 participants, which offered a reasonable instructor-to-attendee ratio to accommodate the highly immersive and discursive aspects of a design thinking approach. We sought an equal number of digital humanities researchers and digital humanities professionals. We clarified that digital humanities professionals were people like librarians, consultants, and other institutional staff who conduct digital humanities text data mining or aid researchers in their text data mining research. We aimed for the same number of DH research and DH professionals because these two groups were differently situated in their organizations to provide future advocacy and support. We also anticipated the two groups will have mutually beneficial insights and experiences to share. For instance, DH researchers benefitted from LLTDM training that can be both applied to their own research projects and publications, as well as integrated into their teaching and advising, thereby broadening downstream community impact. Conversely, DH professionals are often the first contact point for DH researchers with law-related TDM questions; handle licensing and negotiate access to datasets and digital collections for TDM; and provide training and documentation for DH researchers on workflows and tools. Educating DH professionals enables ongoing Institute impact as they bring the skills they have gained back to their own campuses and professional communities. Finally, we encourage participation from pairs of participants (e.g. one digital humanities researcher and one professional affiliated with that same institution, organization, or digital humanities project).
We kept the application process as simple as possible. We asked applications to submit two documents via email: 1) a current CV, and 2) a 2-page (maximum) letter of interest that addressed their experience with or interest in: the intersection of text data mining in digital humanities research and the law; your goals for applying knowledge and skills to be acquired at the Institute to your own activities; your goals for sharing knowledge and skills with others at your home institutions/affiliations; and, how you might support the Institute’s commitment to diversity and equity.
Participant selection criteria and process
We communicated our selection criteria on the Building LLTDM website. The call for applications was open for two months.
The project team believed that the Institute will work best when it reflects the race and gender demographics of the broader population, and not just those of higher education—and we strived to achieve equity by reflecting these more representative demographics. Additionally, we worked to develop a participant group that is representative of different institution types, research advising and support experience, professional roles, levels of experience with digital humanities text data mining research career stages, and disciplinary perspectives.
The selection process took place over two rounds. First, a subset of the project yeam conducted an initial screen of applications giving preference for the criteria identified below:
- Digital humanities researcher or professional
- Experience working with at least one digital humanities text data mining project
- Articulated interest in the relationship between text data mining and the law
- Articulated reason for participating in the Institute
- Clear post-Institute goals or ideas for using and sharing knowledge and skills gained
- Application as part of a researcher/professional pair
- Demonstrated commitment to diversity and equity
The project team then performed a second review of applications, making final selections based on the selection criteria and diversity principles identified above.
Since Building LLTDM was made possible through a federal grant (National Endowment for the Humanities Institute for Advanced Topics in the Digital Humanities), we were only able to accept participants based in the United States.
Financial support for participants & instructors
Participant stipends
We offered participant stipends that were distributed to them in advance of the Institute, rather than requiring participants to incur all travel, lodging, and meal expenses and then wait for reimbursement. Our aim was for participants to have zero out-of-pocket costs to attend the Institute. We issued comprehensive stipends because of the social justice implication, as prospective diverse participants may be dissuaded from applying if they know that travel and lodging costs must be charged to a credit card several months in advance of attendance. As a preliminary matter, potential participants may not have credit cards to use for such expenses and, even if they do, they further may not be able to afford accruing high rates of interest while awaiting reimbursement until after the Institute. To ensure a diverse applicant pool and establish participatory equity for all prospective applicants, we believe it is critical to offer realistic stipends from which participants can cover their costs so they do not have to pay for the Institute out-of-pocket.
We structured the stipends as the equivalent of what we anticipate the participants’ actual travel, lodging, and meal expenses will be. We have estimated participant costs based on potential geographic zones from which they would have been traveling. Due to the Covid-19 pandemic, Building LLTDM was conducted entirely online. As the participant stipends were already being processed, and with permission from our NEH program officer, we decided it was fair and efficient to simply deliver the original agreed-upon amount to each participant, even though there was no travel and lodging costs incurred.
Instructor honoraria
We offered instructor honoraria to be distributed to the project team. We awarded honoraria to serve two functions: (1) to recognize the personal (non-work) contributions being made by the project team, and (2) to provide compensation for travel, food, and lodging for the project team members traveling to the Building LLTDM Institute. As with participant stipends, we structured the instructor honoraria as the equivalent of what we anticipate the instructors’ actual travel, lodging, and meal expenses will be—plus some compensation to reward their efforts in preparing Institute educational materials, offering instruction during the Institute, and creating the open educational resource following the Institute.
Due to the Covid-19 pandemic, Building LLTDM was conducted entirely online, and the instructors decided to each receive an equal share of the honoraria allotment, since there was no travel or lodging incurred.
Institute communications
We leveraged several different communication methods, some focusing on internal communications to and between faculty and participants, and some focusing on public communications about the Institute.
Internal communications
For internal communication between faculty to plan the Institute content and delivery preparation, we used a Google Group email.
We set up a separate email group so prospective and accepted participants could ask questions to the LLTDM organizers (those responsible for viewing and answering the email were the Project Director and Project Manager).
For internal communication to participants, we at first used email by cc-ing all participants. For the actual delivery of the online Institute, we relied on a combination of Slack and email. We used slack for announcements, information sharing, and reminding participants and faculty of upcoming sessions. Faculty and participants created additional Slack channels separate from the #general channel to discuss specific TDM research areas, such as #social-media ad #oral-histories. In the weeks leading up to the Institute, we asked both faculty and participants to introduce themselves in an #introductions channel on Slack.
In order to orient faculty about how we would deliver the Institute together, we developed and shared a Faculty Facilitation Guide (we called it the “Faculty Packet”). This Google doc contained faculty and participant contact information, information about how to use Zoom effectively, and both participant and faculty expectations about contributing and interacting during the online Institute.
We also created a comprehensive guide for participants that we called the “Participant Packet” that was distributed in advance of the Institute. The Participant Packet included:
- Instructions for how to communicate with faculty and other participants
- How to ask questions and receive answers during the Institute
- How to use Zoom during out synchronous sessions
- The Institute code of conduct
- Information about social media and Chatham House Rule
The Participant Packet included a detailed day-by-day agenda for the Institute, including assigned meeting groups of various sizes (plenary, small group), free-write activities, and also links to Zoom rooms and shared notes documents for each session.
Importantly, the Participant Packet contained links to readings and pre-recorded short videos (with transcripts and slides) so that participants could be prepared for the next day’s topics.
We viewed the Participant Packet as the one-stop-shop for both participants and faculty to be able to reference throughout the week, as it contained nearly all the information we needed to deliver the Institute.
Public communications
We engaged in some public communications around Building LLTDM. We created a website that contained public-facing information about the Institute, including background information and why the Institute was needed, introduction of the project team, contact information, and information about how to apply (including process, selection criteria, stipend, logistics, and code of conduct). We included a page that discussed how we would be publishing the content and curriculum from the Institute later as an Open Educational Resource (OER). The website was built on WordPress, so it was easy to include a “news” (essentially a blog) section in order to make announcements, provide updates, and discuss outcomes of Building LLTDM. We asked our Library Communications Team to design a simple logo for the Institute, which we used on the website.
We advertised the LLTDM opportunity through our Library’s Office of Scholarly Communication Services Twitter account, and urged other faculty to do the same, either through their institutional or personal social media accounts.
In order to provide easy viewing to all the pre-recorded TDM topical videos, we uploaded them all to the Office of Scholarly Communication Services YouTube account. Viewers can also speed up or slow down the video playback, or turn on closed captions; both features are offered automatically by YouTube. We also created playlists under each topical area (copyright, international copyright, licensing, technological protection measures, and privacy & ethics), as well as a comprehensive playlist containing all the videos.
Code of conduct
Building LLTDM participants and faculty were subject to a code of conduct. We drafted our code of conduct based on examples from several other initiatives. The purpose of including a code of conduct was to provide a positive, inclusive, and harassment-free experience for everyone participating in the Institute. The code of conduct outlined the types of behaviors we were aiming to uphold, and described the types of harassing behaviors that would not be tolerated. The code of conduct included information about how to report an incident.
Institute preparation
Participant questionnaire
About a month before the online Institute, we sent a short questionnaire to participants to complete so that the faculty instructors could learn more about their research and professional practices related to text data mining. The responses were compiled into a PDF and shared with the project team prior to the start of the Institute. It allowed faculty to better understand the participants’ real-world research experiences and tailor the online sessions and exercises to properly meet participant expectations and needs.
Background reading
We intentionally kept the amount of preparation for the Institute to a minimum, both because we knew the participants were busy individuals with full time jobs and research responsibilities, and also due to the added pressure and stresses of the Covid-19 pandemic. We set the expectation that we hoped the participants would be able to provide as much undivided attention as they could during the actual week of delivery (of course understanding that there might be necessary interruptions due to family or personal responsibilities because of the remote nature of the workshop). We suggested just two pre-reading to set the stage for our week together online. These readings provided an overview of the TDM legal and policy environment.
- Matthew Sag, “The New Legal Landscape for Text Mining and Machine Learning,” SSRN Electronic Journal, 2019, https://doi.org/10.2139/ssrn.3331606
- Rachael Samberg and Cody Hennesy, “Law and Literacy in Non-Consumptive Text Mining: Guiding Researchers Through the Landscape of Computational Text Analysis,” in Copyright Conversations: Rights Literacy in a Digital World, edited by Sara Benson (Chicago: Association of College and Research Libraries, 2019), https://escholarship.org/uc/item/55j0h74g
